{kind=link}
支持向量机在ICU急性肾损伤患者住院死亡风险预测中的应用
[蔺轲1, 2 , 谢俊卿1, 2 , 胡永华1, 2 , 孔桂兰2, △  ]
]
]
|
|


急性肾功能损伤(acute kidney injury, AKI)是住院患者常见的危重症之一。AKI患者具有较高的死亡率和发展为慢性肾脏病的风险[1]。虽然近年来的诊疗水平不断提高, 但AKI所带来的疾病负担仍然十分沉重, 这一情况在重症监护室(intensive care unit, ICU)尤为严重[2], 因此, 评价ICU中AKI患者病情的严重程度并预测其住院死亡风险, 对AKI患者的死亡风险识别、评价ICU医疗质量和合理利用医疗资源均至关重要。急性生理学和慢性健康状况评分(the acute physiology and chronic health evaluation Ⅱ , APACHE-Ⅱ )[3]、简化急性生理评分(the simplified acute physiology score Ⅱ , SAPS-Ⅱ )[4]等ICU常用危重症病情评分系统是目前量化ICU中AKI患者住院死亡风险最常用的手段之一。然而, 近年来随着医疗信息化程度不断提高, 绝大多数诊疗信息能够以数字化形式得以保存, 这为开发新的死亡风险预测模型提供了可靠而丰富的数据来源。另一方面, 数据挖掘与机器学习技术的蓬勃发展为开发新的死亡风险预测模型提供了理论基础。支持向量机(support vector machine, SVM)是20世纪90年代中期由Vapnik等[5]根据结构风险最小化的原则提出的一种机器学习方法, 在ICU死亡风险预测领域得到了良好的应用[6]。SVM有坚实的统计学理论作为支撑, 与其他预测模型相比具有优越的预测性能[7]。目前缺乏使用SVM预测ICU中AKI患者死亡风险的研究, 因此, 本文以国外大型重症医疗数据库重症监护医学信息市场(medical information mart for intensive care Ⅲ , MIMIC-Ⅲ )为数据源, 利用SVM构建ICU中AKI患者的住院死亡风险预测模型, 并比较其与传统的SAPS-Ⅱ 评分系统的预测性能。
本次研究的患者来自于MIMIC-Ⅲ 大型重症医疗数据库[8], 该数据库由美国麻省理工学院计算生理学实验室、美国哈佛医学院贝斯以色列迪康医学中心于2015年8月合作建立并维护, 存储了近5万例ICU患者的临床信息, 3亿多条结构化数据, 包括了每例患者人口学特征、诊断编码、实验室检验和检测结果、医疗干预记录、出院记录等。国内外基于MIMIC-Ⅲ 数据库的上一版本MIMIC-Ⅱ 已有大量的文献发表和科学发现, MIMIC-Ⅲ 数据库在MIMIC-Ⅱ 的基础上增加了2008— 2012年的数据, 并改善了数据质量。MIMIC-Ⅲ 数据库是重症医学领域临床研究的宝库, 其数据经过严格的去隐私处理并对全球研究人员免费开放。该数据库不仅样本量大、数据类型丰富, 而且数据质量好、可靠性高。
本研究的结局变量为ICU中AKI患者的存活状态, 模型预测的结果为每个AKI患者的住院死亡概率。本研究使用2012年国际改善全球肾脏病预后组织(Kidney Disease: Improving Global Outcomes, KDIGO)发表的《急性肾损伤临床实践指南》[9]作为AKI患者的诊断标准, 即:48 h内血肌酐增高≥ 26.5 μ mol/L; 或血肌酐增高至基线值的 1.5倍以上, 且明确或推测其在之前的7 d内发生; 或持续6 h 尿量0.5 mL/(kg· h)。血肌酐的基线值取患者入ICU后的第一次测量值。
为了更加客观地比较SVM和SAPS-Ⅱ 之间的性能, 本研究使用SAPS-Ⅱ 评分系统中所用到的全部变量构建SVM模型, 这些变量包括:入ICU后24 h 内的12 项生理指标、年龄、入院类型(计划手术、非计划手术、无手术), 以及是否合并艾滋病、转移癌、血液系统恶性肿瘤。在这些变量中, 某些生理指标是重复测量的, 例如心率、血压、体温等。这类重复测量变量由于数据量庞大, 不宜将每次测量的数据都放入模型。在构建SAPS-Ⅱ 模型的过程中, 我们按照SAPS-Ⅱ 原始文献[4]中所提供的方法对变量进行处理, 具体的处理方法为:对于只有唯一取值的变量, 如年龄、性别等变量, 根据变量的取值不同, 分别赋予不同的分值。对于重复测量的变量, 根据SAPS-Ⅱ 原始文献的规则选取该变量的最大值或最小值, 并据此赋予不同的分值。在构建SVM模型时, 对于只有唯一取值的变量, 我们直接取该变量的原始值, 对于重复测量的变量, 我们仅提取各个重复测量变量在入ICU后24 h内的最大值和最小值。
(1)纳入标准:年龄≥ 18岁且≤ 90岁; 符合KDIGO诊断标准; (2)排除标准:一次住院期间多次入ICU的患者; 变量缺失率超过30%的患者。
1.4.1 SVM模型 SVM的目标是在高维空间中创建一个最佳的分类边界(最大间隔超平面), 从而将不同类别的样本区分开来。最大间隔超平面是与其最接近的点之间的距离达到最大的分类边界。支持向量即指每个类中最接近最大间隔超平面的点[7, 10]。
以下为在给定特征空间上包含N个样本点的训练数据集:
其中,
SVM中的决策函数可以如下表示:
其中,
SVM分类器需要满足以下条件:
等式
其中, C是惩罚参数, C值越大对误分类的惩罚增大, C值越小对误分类的惩罚减小。
其中, k(xi, xj)=< φ (xi), φ (xj)> , 是将输入向量映射到特征空间的核函数。当对偶问题解决后, SVM决策函数可以表达为:
本研究利用R软件中的kernlab软件包进行SVM建模, 惩罚参数设为1, 核函数采用径向基函数。预测变量为SAPS-Ⅱ 模型中各变量的原始值, 其中重复变量包含最大值和最小值。输出结果为每个AKI患者的住院死亡概率。
1.4.2 SAPS-Ⅱ 模型 SAPS-Ⅱ 是一个基于Logistic回归开发的危重症评分系统, 被广泛地用于评估ICU患者病情严重程度和死亡风险, 具体的使用方法为:根据患者的情况, 对SAPS-Ⅱ 中各个变量进行打分, 然后计算每个患者的总得分, 进而根据原始文献中提供的公式计算出每个患者的住院死亡风险。具体的公式如下:
其中,
1.4.3 定制版SAPS-Ⅱ 模型 由于SAPS-Ⅱ 开发于20世纪90年代, 各变量的系数是基于当时的ICU人群计算得来, 故将SAPS-Ⅱ 模型直接应用于目前的ICU人群时, 模型的性能往往不如人意。一个可行的解决办法是使用当前数据定制本地化的模型, 即以患者的结局为因变量, 以SAPS-Ⅱ 模型中各变量的得分值为自变量, 建立Logistic回归模型, 进而以该回归模型的系数计算患者的死亡风险。本研究参照Moreno等[11]的方法用MIMIC-Ⅲ 数据库定制了SAPS-Ⅱ 模型, 并将定制版的SAPS-Ⅱ 模型作为SVM模型的比较对象。具体的定制方法为:
New logit=
其中,
数据的提取与清洗使用PostgreSQL数据库, 数据分析与模型建立使用R软件。各变量的缺失值用该变量的均值替代。模型性能的评价使用五折交叉验证, 即将现有的数据随机分为5等份, 每一份都单独作为测试集, 其余4份作为训练集。在训练集中分别利用SVM、SAPS-Ⅱ 和定制版SAPS-Ⅱ 构建预测模型, 在测试集中计算受试者工作特征(receiver operation characteristic, ROC)曲线下面积(area under the ROC curve, AUROC)、均方根误差(root mean squared error, RMSE), 并通过ROC曲线确定最佳截断值, 从而计算灵敏度、特异度、约登指数和准确率。模型进行性能比较时, 我们取5次结果的平均值进行比较。使用配对t检验评价各模型5次结果之间的差异是否有统计学意义。另外, 为了更深入地探究SVM模型与SAPS-Ⅱ 模型预测性能的差异所在, 我们使用Bland-Altman分析评价了两模型预测性能之间的一致性。Bland-Altman分析是一种以图形化的方式评价两种测量手段结果一致性的方法, 被广泛用于放射医学、超声医学、实验室医学等临床领域, 该方法既能分析不同预测模型的一致性, 亦能找出不同预测模型之间的差异性所在。
经过数据清洗, 本研究共纳入19 044例AKI患者, 死亡率为 13.58%, 平均年龄(63.75± 16.13)岁, 男性患者有11 202例, 占比58.82%。患者的平均SAPS-Ⅱ 得分为(38.95 ± 14.53)分。患者的详细信息见表1。
| 表1 AKI数据的基本特征 Table 1 Characteristics of AKI data in MIMIC-Ⅲ |
SVM模型、SAPS-Ⅱ 模型和定制版SAPS-Ⅱ 模型的预测性能见表2, 可以看出SVM模型在AUROC、RMSE和约登指数方面的表现均为最优。对于SAPS-Ⅱ 模型, 经过定制之后, SAPS-Ⅱ 模型的预测性能有了一定的提升, AUROC由 0.79提升至 0.81, 约登指数由0.45提升至0.47, 准确率由0.74提升至0.76, RMSE由0.36降低至0.31, 但是定制版的SAPS-Ⅱ 模型的预测性能还是弱于SVM模型, 其AUROC比SVM模型低约0.05, 差异具有统计学意义。在RMSE方面, SVM模型优于定制版SAPS-Ⅱ 模型, 差异具有统计学意义。此外, SVM模型在灵敏度和约登指数方面也均优于定制版的SAPS-Ⅱ 模型, 差异均具有统计学意义。
| 表2 3种模型的预测性能比较 Table 2 Comparison of performance of three models |
Bland-Altman见图1, 横坐标为SVM模型和定制版SAPS-Ⅱ 模型预测的患者死亡概率的平均值, 该值作为患者的死亡风险; 纵坐标为SVM模型和定制版SAPS-Ⅱ 模型预测的患者的死亡概率的差值。当患者的死亡风险极低或者极高时, SVM模型和定制版SAPS-Ⅱ 模型的预测结果的一致性很高, 但当患者的死亡风险为50%左右时, 两模型预测结果的一致性很差。
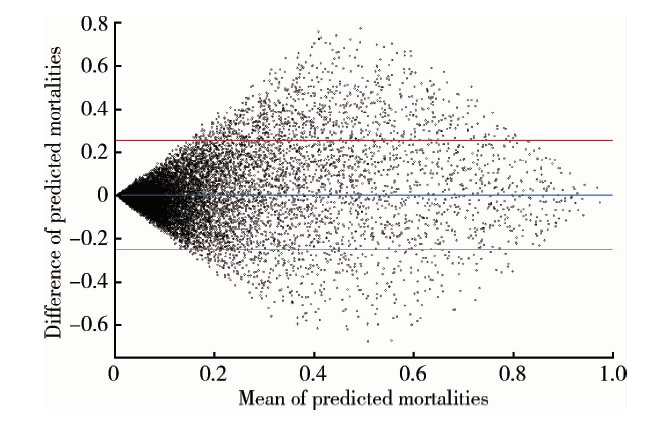 | 图1 Bland-Altman图Figure 1 Bland-Altman plot |
传统的AKI患者死亡风险评价工具主要是各类危重症病情评分系统, 主要包括APACHE-Ⅱ 、SAPS-Ⅱ 等ICU通用病情评分系统, 也有学者尝试为ICU的AKI患者中开发新的死亡风险评价工具[12], 但这些工具都是基于Logistic回归模型开发, 对复杂情况(如变量间的多重共线性)及高维数据的处理能力较差。机器学习技术的发展给我们提供了解决这一问题的全新思路。饶飘雪等[13]使用SVM、人工神经网络、Logistic回归建立了3个用于预测乳腺癌复发的模型, 结果显示相对于Logistic回归模型, SVM和人工神经网络具有更好的预测性能, 其中SVM的预测性能最好。Lee等[14]使用了16个变量分别建立了用于预测老年慢性病患者服药依从性的SVM模型和Logistic回归模型, 结果显示SVM模型和Logistic模型的分类准确率分别是97.3%和71.1%。
本研究我们使用SVM开发了用于预测ICU中AKI患者死亡风险的模型, 并比较其与定制版SAPS-Ⅱ 模型的预测性能。首先, 相对于原始的SAPS-Ⅱ 模型, 定制版SAPS-Ⅱ 模型的性能有了提升, 这说明定制版SAPS-Ⅱ 模型可以更深刻地理解当前数据背后的临床意义, 并且能更好地拟合数据。其次, 在性能指标AUROC和约登指数方面, SVM模型明显优于定制版SAPS-Ⅱ 模型, 差异具有统计学意义。在RMSE方面, SVM模型亦有优势。第三, 通过Bland-Altman分析, 我们发现这主要是大部分AKI患者的死亡风险集中在20%以内, 此时SVM和定制版SAPS-Ⅱ 模型预测结果的一致性较好, SVM模型的优势未能充分体现。但当患者的死亡风险接近50%时, 即死亡风险不确定时, SVM模型和定制版的SAPS-Ⅱ 模型预测结果的一致性很差。结合两模型的AUROC和约登指数的表现, 我们认为SVM模型的性能优于定制版SAPS-Ⅱ 模型, 且当患者的死亡风险不确定时, 这种优势尤其明显。
本研究开发的SVM模型在预测AKI患者的死亡风险方面有很强的临床应用价值。AKI患者往往病情复杂, 死亡率较高。本研究中的AKI患者的死亡率为13.58%, 这与一些AKI的流行病学研究中所报告的死亡率相近[15, 16]。AKI的早期发现和治疗可以改善预后, 降低死亡率, 这一点可以从AKI诊断标准的产生和演变中体现。在AKI的概念提出之前, 普遍使用的概念是急性肾衰竭, 但急性肾衰竭的各种诊断标准都忽视了早期肾损害的病理生理变化, 故而被淘汰。随后提出的危险、损伤、衰竭、肾功能丧失和终末期肾病(risk, injury, failure, loss, end-stage kidney disease, RIFLE)分级诊断标准、急性肾损伤网络(Acute Kidney Injury network, AKIN)分期标准和KDIGO诊断标准都越来越强调AKI的早期诊断与治疗。本研究提供的基于机器学习的SVM模型拥有比传统模型更优秀的预测性能, 更有利于AKI患者的死亡风险识别与早期干预。除此之外, 在临床科研方面, 还可以通过预测的死亡风险来对患者分组, 从而控制组间的可比性。
当然, 本研究亦有不足之处。首先, 尽管MIMIC-Ⅲ 数据库是一个高质量的数据来源, 但它只是一个基于美国人群的单中心数据库, 因此所得结论在模型外推方面存在一定的局限性, 其预测效果在其他人群, 尤其是中国人群的适用性仍需多中心的外部验证。由于伦理限制及硬件条件限制, 本次研究尚未获取到国内ICU中AKI患者的数据, 我们下一步研究将着眼于用中国人群的数据验证SVM模型的预测性能。其次, 基于数据变量的限制, 本研究未引入APACHE-Ⅱ 评分。以往有研究表明[17]APACHE-Ⅱ 评分系统对AKI患者预后的判断价值比SAPS-Ⅱ 更优。Luaces等[18]的研究发现, 在预测ICU患者死亡率方面, SVM模型的性能优于APACHE。由于MIMIC-Ⅲ 数据库中缺少APACHE-Ⅱ 的部分变量, 本研究未能对比SVM模型、APACHE-Ⅱ 和SAPS-Ⅱ 三者的性能。
综上所述, 相比于传统的SAPS-Ⅱ 模型, SVM模型的性能更优, 更适合预测ICU中AKI患者死亡风险。我们推荐在当前大数据时代, 临床医疗信息化程度很高的情形下, 应用计算机化的、基于SVM的住院死亡风险预测系统来辅助ICU医生进行临床决策和干预, 能够有效地帮助ICU内临床医生降低医疗差错、提高医疗质量。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|